-
Hierarchical Clustering (Agglomerative Algorithm)Data/Machine learning 2021. 1. 7. 12:05
Hierarchical clustering provides an intuitive graphical display (e.g. dendrogram). However, it cannot be used with a large dataset. For even a modest-sized dataset with just tens of thousands of records, it can require intensive computing resources. In fact, most of the applications of hierarchical clustering are focused on relatively small datasets.
Algorithm (Hierarchical Clustering = Agglomerative Algorithm)
[NOTE] the algorithm explained here can work in the same way even when the features and samples are reversed. Two types of dendrograms: 1) dendrogram w.r.t features, 2) dendrogram w.r.t samples
The process of the algorithm can be summarized as follows: The hierarchical clustering starts by setting each record as its own cluster and iterates to combine the least dissimilar clusters. It can be furthered as follows:
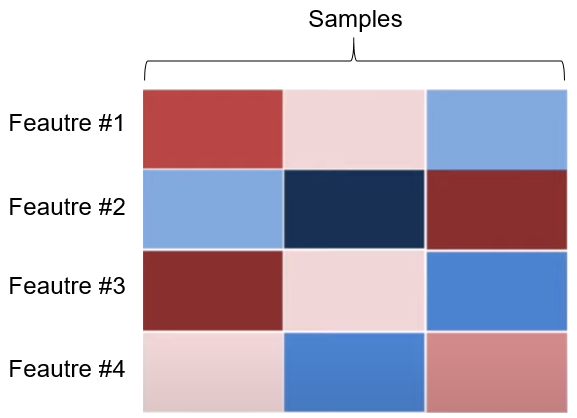
- Figure out which feature is most similar to feature #1.
- Figure out which feature is most similar to feature #2.
- The above step is applied to feature #3 and feature #4.
- Figure out which two features are the most similar, and merge them into a cluster.
For the similarity metric (distance metric), there are several of them: Euclidean distance, Manhattan distance, etc. From the step 4, we find that feature #1 and feature #3 are the most similar, so we merge them into a cluster:
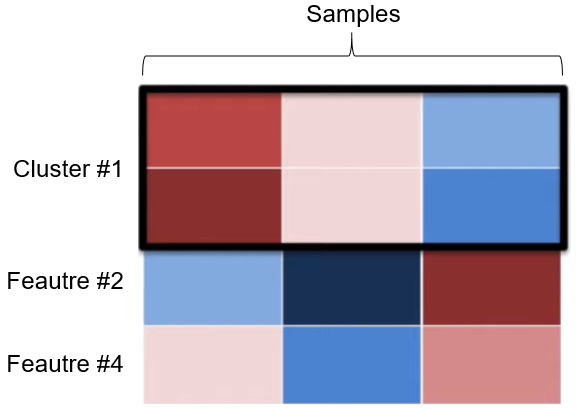
And it goes on and on until we end up with one giant cluster. Note that there are several approaches to compare the distance metric between clusters:
1) the average of each cluster (called "centroid")
2) the closest point in each cluster (called "single-linkage")
3) the furthest point in each cluster (called "complete-linkage") $\rightarrow$ most commonly used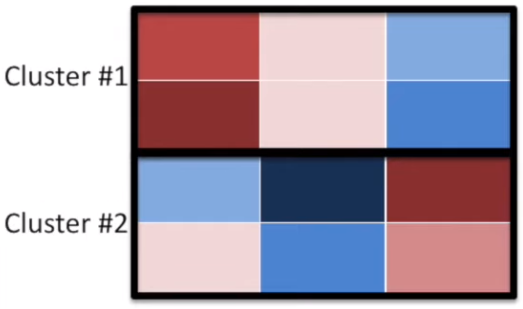
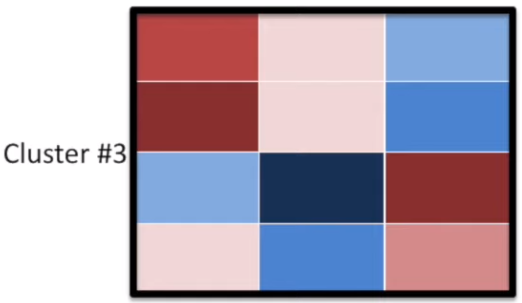
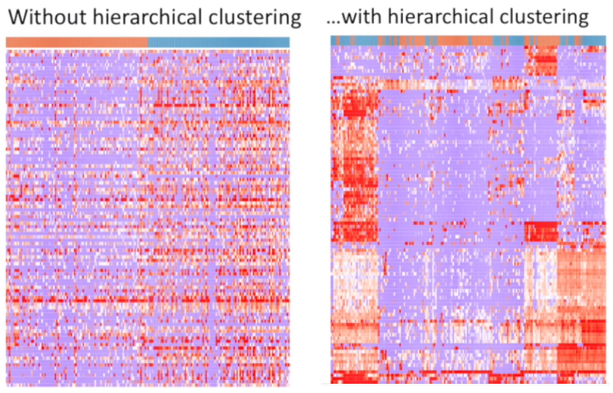
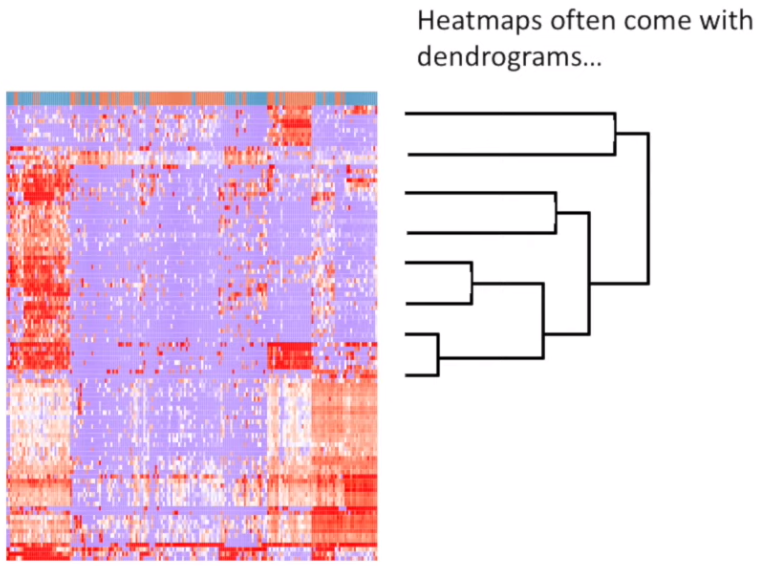
The hierarchical clustering is usually accompanied by a dendrogram. It indicates both the similarity and the order that the clusters formed.
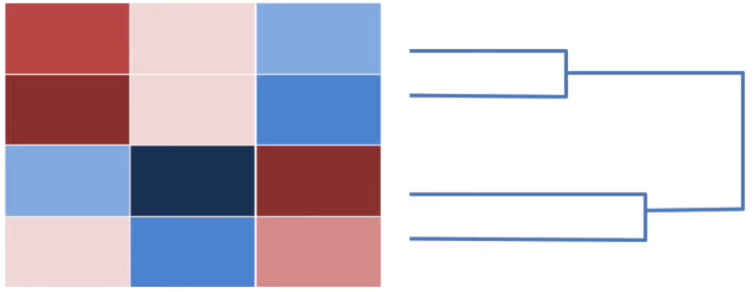
Dendrogram 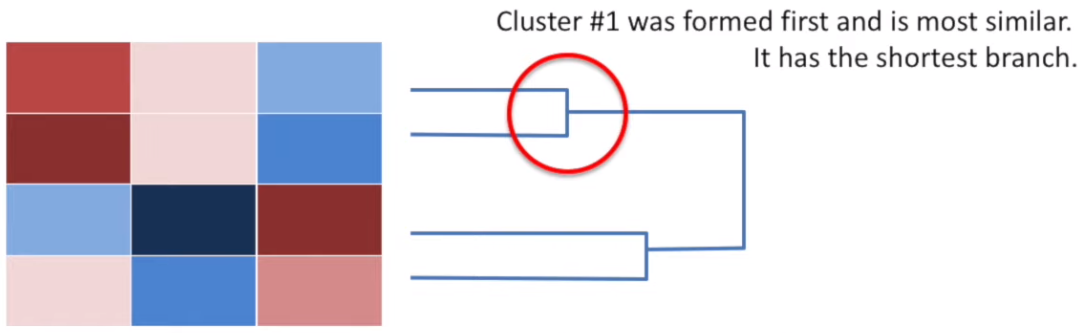
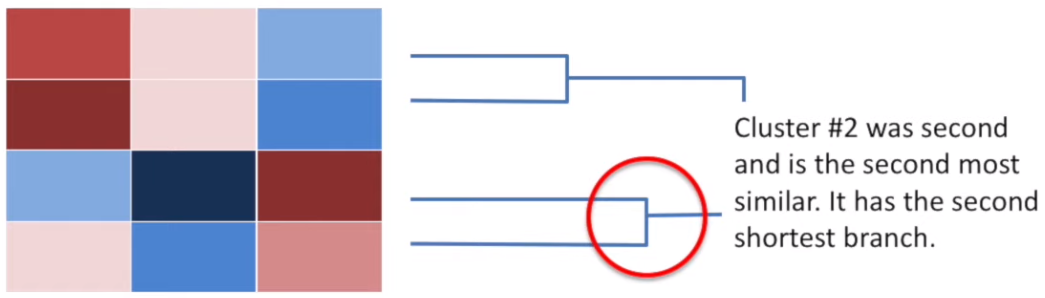
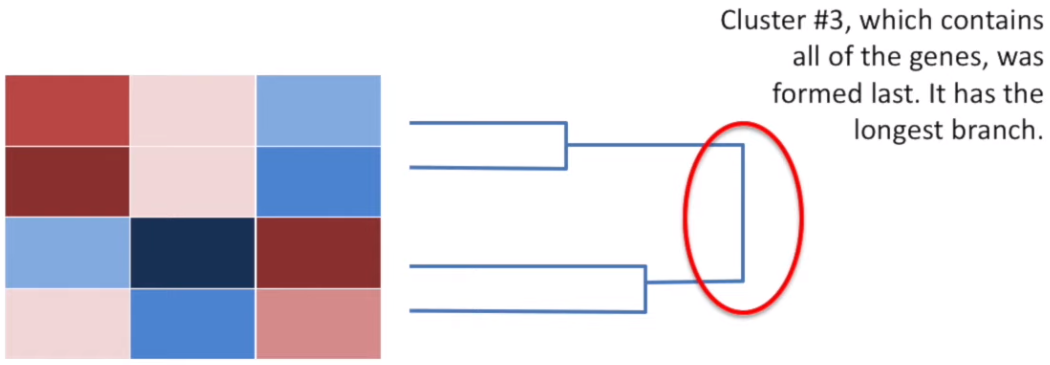
Example
'Data > Machine learning' 카테고리의 다른 글
Outlier Detection with Multivariate Normal Distribution (0) 2021.01.08 K-means implementation in GoogleColab (0) 2021.01.06 Ensemble, Bagging, and Random Forest (0) 2021.01.06