-
K-means implementation in GoogleColabData/Machine learning 2021. 1. 6. 17:02
Implementation of K-means in GoogleColab to take a close look at the process of the K-means (link here).
Result
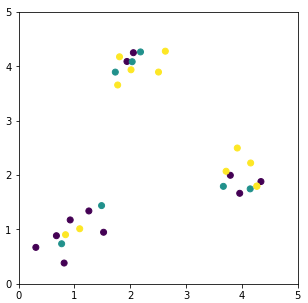
The used dataset is as follows:

1. Assign the initial cluster means (by randomly assigning each record to one of the $K$ clusters)
Then, the (initial) cluster means are the means of the assigned records to each cluster:
$$ \bar{x}_k = \frac{1}{n_k} \sum_{i \in k}^{n_k}{x_i} $$
$$ \bar{y}_k = \frac{1}{n_k} \sum_{i \in k}^{n_k}{y_i} $$
where $k$ denotes class.
2. Compute the Euclidean distance of each record to each cluster mean, and assign them to the closest cluster mean
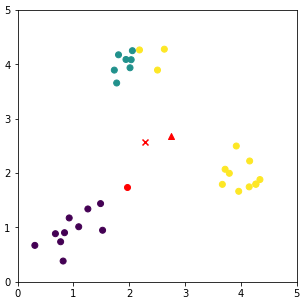
the cluster means were computed in step 1 3. Compute the new cluster means given the records that were assigned the corresponding cluster means

4. Repeat steps 2-3


'Data > Machine learning' 카테고리의 다른 글
Hierarchical Clustering (Agglomerative Algorithm) (0) 2021.01.07 Ensemble, Bagging, and Random Forest (0) 2021.01.06 Bayesian neural network (0) 2020.10.22