-
Transformer Study MaterialsData/Machine learning 2021. 12. 4. 16:24
1. https://youtu.be/z1xs9jdZnuY
2. https://youtu.be/4Bdc55j80l8
About Positional Encoding
https://kazemnejad.com/blog/transformer_architecture_positional_encoding/
Transformer Architecture: The Positional Encoding - Amirhossein Kazemnejad's Blog
Transformer architecture was introduced as a novel pure attention-only sequence-to-sequence architecture by Vaswani et al. Its ability for parallelizable training and its general performance improvement made it a popular option among NLP (and recently CV)
kazemnejad.com
Masked Self-Attention
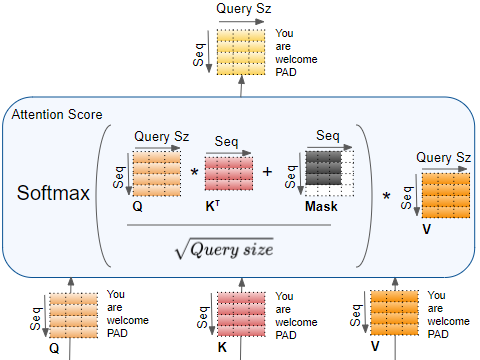
Application: Time series forecasting with Transformer's decoder architecture: https://github.com/nklingen/Transformer-Time-Series-Forecasting/blob/main/model.py
'Data > Machine learning' 카테고리의 다른 글
Vision Transformer (ViT) Study Material (0) 2021.12.05 Machine learning - Introduction to Gaussian processes (0) 2021.09.15 Evidence Lower Bound (ELBO) (0) 2021.08.24